
인공지능 모델의 성능을 정확히 평가하는 것은 개발의 핵심 단계입니다. 특히 데이터를 기반으로 특정 클래스를 예측하는 분류모델에서는 다양한 평가지표를 이해하고 올바르게 사용하는 것이 중요하합니다.
이번 글에서는 지난 시간의 회귀모델 평가지표에 이서 대표적인 분류모델 평가지표들에 대해서 살펴 보도록 하겠습니다.
💡 분류 모델 평가지표, 왜 중요할까요?
우리가 인공지능 모델을 만드는 이유는 현실의 복잡한 문제를 해결하기 위함입니다. 예를 들어, 어떤 환자가 특정 질병에 걸렸는지 예측하거나, 스팸 메일을 정확히 분류하는 것 등이 대표적이죠.
이때 단순히 ‘예측이 맞았다/틀렸다’만으로 모델의 성능을 판단하기에는 무리가 있습니다. 어떤 유형의 오류가 발생했는지, 그리고 그 오류가 실제 상황에서 어떤 결과를 초래하는지 이해하는 것이 매우 중요하기 때문이에요.
예를 들어, 암 진단 모델의 경우 ‘암인데 암이 아니라고 예측(음성 오류)’하는 것은 ‘암이 아닌데 암이라고 예측(양성 오류)’하는 것보다 훨씬 치명적일 수 있습니다.
이처럼 상황과 목적에 따라 우리는 다른 관점에서 모델의 성능을 측정해야 해요. 따라서 다양한 평가지표를 이해하고 적절히 활용하는 것은 모델의 신뢰성을 높이고, 실제 적용 시 발생할 수 있는 위험을 최소화하는 데 필수적입니다.
📊 분류 모델 평가지표의 기본 개념: 혼동 행렬 (Confusion Matrix)
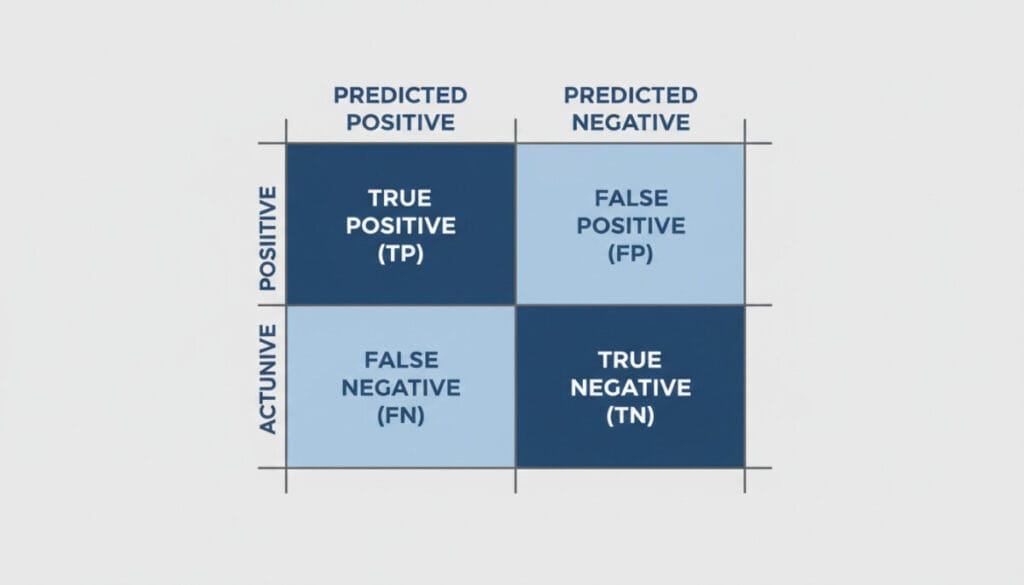
분류 모델의 성능을 평가할 때 가장 기본이 되는 도구는 바로 혼동 행렬(Confusion Matrix)입니다. 혼동 행렬은 실제 값과 예측 값을 비교하여 모델의 예측이 어떤 유형의 정답과 오답을 만들었는지 한눈에 보여주는 표예요. 이를 통해 우리는 정확도, 정밀도, 재현율 등 다양한 평가지표를 계산할 수 있습니다.
혼동 행렬의 네 가지 요소는 다음과 같습니다:
- True Positive (TP): 실제 ‘참’인 것을 모델이 ‘참’으로 정확하게 예측한 경우 (정답)
- True Negative (TN): 실제 ‘거짓’인 것을 모델이 ‘거짓’으로 정확하게 예측한 경우 (정답)
- False Positive (FP): 실제 ‘거짓’인 것을 모델이 ‘참’으로 잘못 예측한 경우 (오답, 1종 오류)
- False Negative (FN): 실제 ‘참’인 것을 모델이 ‘거짓’으로 잘못 예측한 경우 (오답, 2종 오류)
💡 팁: FP는 ‘실제로 양성이 아님에도 양성으로 잘못 판단’하는 것이고, FN은 ‘실제로 양성임에도 음성으로 잘못 판단’하는 것입니다. 이 두 가지 오류 유형에 대한 이해는 각 평가지표의 의미를 파악하는 데 매우 중요해요.
✨ 핵심 분류 모델 평가지표 종류와 사용법
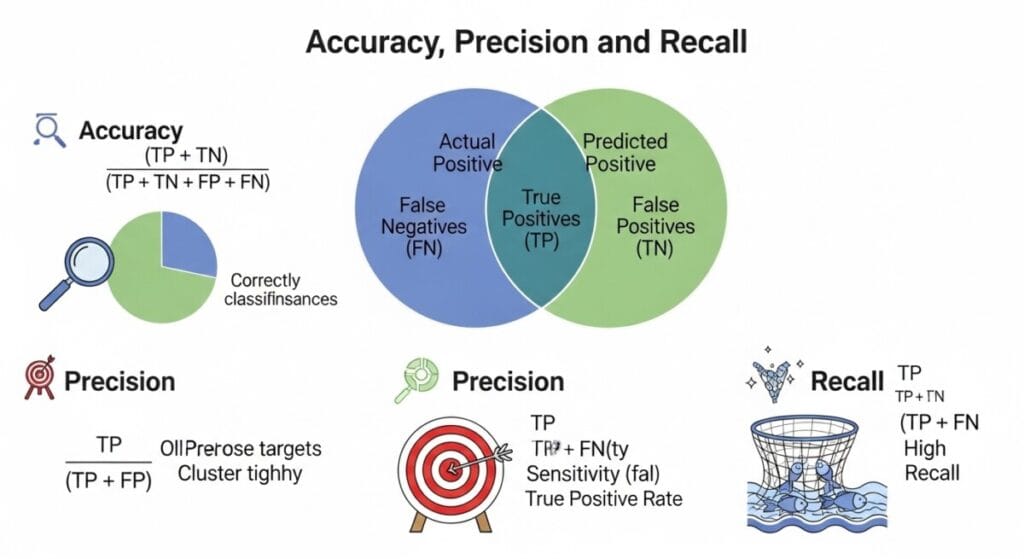
이제 혼동 행렬의 각 요소를 바탕으로 계산되는 주요 평가지표들을 살펴보겠습니다. 각 지표는 모델의 다른 측면을 강조하므로, 상황에 맞는 선택이 필요해요.
1. 정확도 (Accuracy)
모델이 전체 예측 중 얼마나 많은 경우를 정확하게 맞췄는지를 나타내는 지표입니다. 가장 직관적이고 이해하기 쉬운 지표죠.
Accuracy = (TP + TN) / (TP + TN + FP + FN)
- 장점: 이해하기 쉽고 직관적입니다.
- 단점: 데이터 불균형(imbalanced data) 문제 발생 시 모델 성능을 왜곡할 수 있습니다. 예를 들어, 100개 중 99개가 음성이고 1개가 양성인 데이터에서 모든 것을 음성으로 예측하면 정확도는 99%가 되지만, 양성 사례는 전혀 맞추지 못하는 문제가 발생합니다.
2. 정밀도 (Precision)

모델이 ‘참’이라고 예측한 것들 중에서 실제로 ‘참’인 비율을 나타냅니다. FP(실제 거짓인데 참이라고 예측)를 얼마나 줄였는지에 초점을 맞춘 지표예요.
Precision = TP / (TP + FP)
- 장점: 오탐(False Positive)의 비용이 큰 경우(예: 스팸 메일이 아닌 것을 스팸으로 분류)에 중요합니다.
- 단점: 실제 ‘참’인 것을 놓치는 경우(FN)에 대해서는 고려하지 않습니다.
3. 재현율 (Recall, Sensitivity)
실제 ‘참’인 것들 중에서 모델이 ‘참’으로 정확하게 예측한 비율을 나타냅니다. FN(실제 참인데 거짓이라고 예측)를 얼마나 줄였는지에 초점을 맞춘 지표입니다.
Recall = TP / (TP + FN)
- 장점: 미탐(False Negative)의 비용이 큰 경우(예: 암 환자를 정상으로 오진)에 매우 중요합니다.
- 단점: 실제 ‘거짓’인 것을 잘못 예측하는 경우(FP)에 대해서는 고려하지 않습니다.
4. F1-점수 (F1-Score)
정밀도와 재현율의 조화 평균(harmonic mean)으로, 두 지표가 균형을 이룰 때 높은 값을 가집니다. 정밀도와 재현율 중 어느 한쪽만 높아서는 안 되는 상황에 유용합니다.
F1-Score = 2 * (Precision * Recall) / (Precision + Recall)
- 장점: 데이터 불균형이 있을 때 정확도보다 더 신뢰할 수 있는 지표입니다. 정밀도와 재현율의 균형을 종합적으로 평가합니다.
- 단점: 직관적인 해석이 어려울 수 있으며, 상황에 따라 정밀도나 재현율 중 한쪽이 더 중요한 경우 직접적인 판단을 흐리게 할 수 있습니다.
5. ROC 곡선과 AUC (Receiver Operating Characteristic Curve & Area Under the Curve)
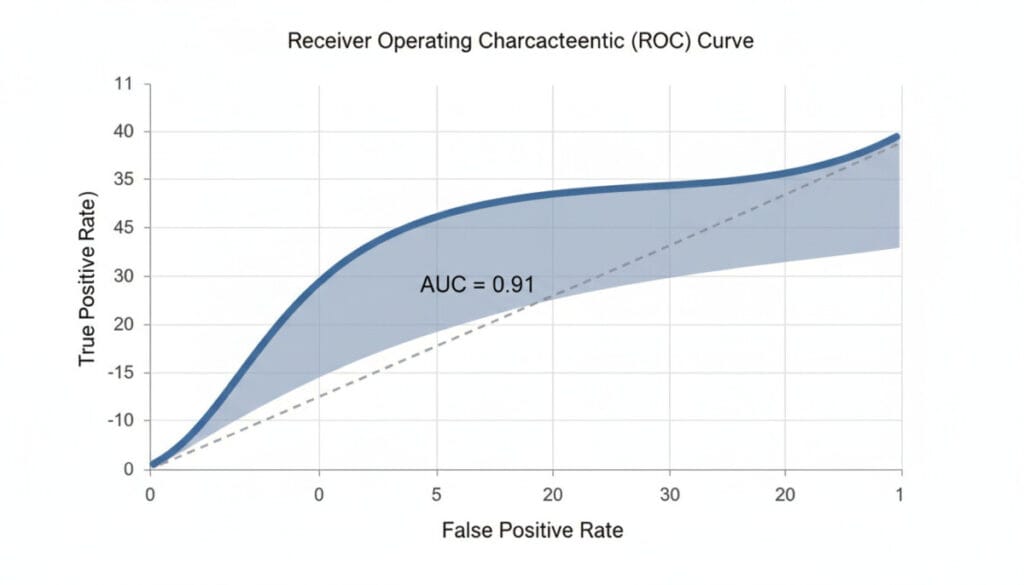
ROC 곡선은 분류 모델의 임계값(Threshold)을 변경하면서 TPR(True Positive Rate, 재현율)과 FPR(False Positive Rate)의 변화를 시각화한 그래프입니다. AUC는 이 ROC 곡선 아래 면적을 의미하며, 1에 가까울수록 좋은 모델입니다.
- 장점: 모든 임계값에서의 성능을 종합적으로 평가하며, 불균형 데이터셋에서도 비교적 안정적인 지표입니다. 다른 모델과의 성능 비교에 유용합니다.
- 단점: 특정 임계값에서의 성능을 직접적으로 보여주지는 않습니다.
🛠️ 각 평가지표, 언제 어떻게 사용해야 할까요?
평가지표의 선택은 모델이 해결하려는 문제의 특성과 오판의 비용에 따라 달라집니다. 가장 중요한 것은 ‘우리 모델의 어떤 측면을 개선하고 싶은가?’를 명확히 아는 것입니다.
- 정확도(Accuracy): 클래스 분포가 비교적 균등하고, 모든 예측 오류의 중요도가 비슷한 경우에 사용하기 좋습니다. 예: 햄/스팸 분류 (스팸과 햄의 개수가 비슷하고, 오분류의 위험이 크지 않은 경우)
- 정밀도(Precision): FP(거짓 양성)의 비용이 매우 큰 경우에 중요합니다. ‘양성으로 예측한 것들 중 진짜 양성이 얼마나 되는가’가 핵심이죠. 예: 스팸 메일 분류(정상 메일을 스팸으로 분류하여 중요한 정보를 놓치게 할 때), 고객에게 추천 상품을 제안할 때(잘못된 추천은 고객 불만으로 이어질 수 있음)
- 재현율(Recall): FN(거짓 음성)의 비용이 매우 큰 경우에 중요합니다. ‘실제 양성인 것들 중 모델이 얼마나 잘 찾아냈는가’가 핵심이에요. 예: 암 진단(암 환자를 정상으로 오진하면 치명적), 금융 사기 탐지(사기를 놓치면 큰 손실 발생)
- F1-점수(F1-Score): 데이터 불균형이 심하거나, 정밀도와 재현율 모두 중요하게 고려해야 할 때 사용합니다. 예: 긍정/부정 감성 분류(긍정/부정 데이터의 양이 다르고, 둘 다 놓치지 않는 것이 중요할 때)
- ROC AUC: 모델의 전반적인 분류 성능을 비교하거나, 임계값에 둔감한 성능 평가가 필요할 때 유용합니다. 예: 여러 분류 모델 후보 중 가장 성능이 좋은 모델을 선택할 때
⚠️ 주의: 정확도가 높다고 무조건 좋은 모델은 아니에요! 특히 희귀 클래스 예측이 중요한 경우(예: 사기 탐지, 질병 진단)에는 정확도만 보고 모델을 판단하면 큰 오류를 범할 수 있습니다. 항상 데이터의 특성과 문제의 목적을 고려하여 적절한 평가지표를 선택해야 합니다.
💡 핵심 요약
- 혼동 행렬: TP, TN, FP, FN의 4가지 요소로 분류 예측의 모든 경우를 파악하는 기본 도구입니다.
- 정확도(Accuracy): 전체 예측 중 올바른 예측의 비율로 직관적이지만, 데이터 불균형 시 오해를 줄 수 있습니다.
- 정밀도(Precision)와 재현율(Recall): FP(거짓 양성)와 FN(거짓 음성)의 중요도에 따라 선택하며, 각각 오탐과 미탐을 줄이는 데 초점을 맞춥니다.
- F1-점수와 ROC AUC: F1-점수는 정밀도/재현율의 균형을, ROC AUC는 임계값에 둔감한 전반적인 분류 성능을 평가할 때 유용합니다.
모델 평가 지표는 단순히 숫자가 아닌, 실제 비즈니스 및 사회적 맥락을 반영해야 합니다. 문제의 본질을 이해하고 최적의 지표를 선택하는 것이 중요합니다.
❓ 자주 묻는 질문 (FAQ)
Q1: 분류 모델 평가지표는 왜 이렇게 여러 가지가 필요한가요?
A1: 하나의 지표로는 모델의 모든 성능 측면을 완벽하게 설명하기 어렵기 때문이에요. 예를 들어 정확도만 본다면, 데이터 불균형이 심한 경우에도 모델이 좋은 것처럼 보일 수 있습니다.
각 지표는 특정 유형의 오류(예: 거짓 양성 또는 거짓 음성)에 더 민감하게 반응하므로, 문제의 특성과 오류 발생 시의 비용에 따라 가장 적절한 지표를 선택해야 합니다. 다양한 지표를 종합적으로 고려해야 모델의 강점과 약점을 정확히 파악하고 균형 잡힌 평가를 할 수 있습니다.
Q2: 데이터 불균형(Imbalanced Data)이 심할 때, 어떤 지표를 주로 봐야 하나요?
A2: 데이터 불균형이 심한 경우에는 정확도(Accuracy)보다는 정밀도(Precision), 재현율(Recall), F1-점수(F1-Score), 그리고 ROC AUC와 같은 지표들을 주로 봐야 합니다.
특히 소수 클래스의 예측이 중요한 경우(예: 사기 탐지, 질병 진단), 재현율이 매우 중요하며, 정밀도와 재현율의 균형을 보는 F1-점수가 유용합니다. ROC AUC는 임계값에 덜 민감하여 불균형 데이터셋에서도 모델 성능을 비교하는 데 좋은 지표로 활용됩니다.
Q3: ROC AUC 점수가 높으면 항상 좋은 모델인가요?
A3: 일반적으로 ROC AUC 점수가 1에 가까울수록 좋은 모델로 평가되지만, 항상 그렇다고 할 수는 없습니다. ROC AUC는 모든 임계값에서의 전반적인 분류 성능을 나타내므로, 특정 비즈니스 요구사항에 맞는 최적의 임계값에서의 성능을 직접적으로 보여주지는 않습니다.
만약 특정 임계값에서 정밀도나 재현율이 극도로 중요하게 요구되는 상황이라면, ROC AUC가 높더라도 해당 임계값에서의 정밀도/재현율 값을 함께 고려하여 최종 판단을 내려야 합니다.
마무리 하며…

지금까지 인공지능 분류 모델의 주요 평가지표들과 그 사용법에 대해 자세히 알아보았습니다. 정확도, 정밀도, 재현율, F1-점수, 그리고 ROC AUC는 각기 다른 관점에서 모델의 성능을 측정하며, 이들을 적절히 조합하여 사용하는 것이 모델의 진정한 가치를 평가하는 데 중요합니다.
모델 개발 과정에서 어떤 평가지표를 목표로 할지 명확히 설정하고, 그에 맞춰 모델을 최적화하는 과정을 거친다면 더 강력하고 신뢰할 수 있는 인공지능 시스템을 구축할 수 있을 거예요.
빠르게 변화하는 AI 환경 속에서 이 글이 여러분에게 도움이 되기를 바라며 AI로 미래를 준비하는 여러분을 응원합니다. 화이팅!

