인공지능 모델의 성능을 정확히 평가하는 것은 개발의 핵심 단계입니다. 특히 연속적인 값을 예측하는 회귀모델에서는 다양한 평가지표를 이해하고 올바르게 사용하는 것이 중요하죠.
이 글에서는 대표적인 회귀모델 평가지표인
MSE, RMSE, MAE, R-squared, 그리고 Adjusted R-squared의 개념부터 실제 활용법까지 쉽고 명확하게 설명해 드리겠습니다.
🎯 회귀모델 평가지표, 왜 중요할까요?

인공지능 모델은 특정 문제를 해결하기 위해 데이터를 학습합니다. 이 중 회귀모델은 주택 가격 예측, 주식 시장 동향 예측, 기온 예측과 같이 연속적인 수치를 예측하는 데 주로 사용되죠.
모델이 아무리 복잡하고 정교하더라도, 그 예측이 얼마나 정확한지 객관적으로 판단할 수 없다면 실제 문제에 적용하기 어렵습니다.
여기서 바로 평가지표의 역할이 중요해집니다. 평가지표는 모델의 예측값과 실제값 사이의 오차를 수치화하여 모델의 성능을 객관적으로 비교하고 개선 방향을 찾는 데 필수적인 도구입니다.
단순히 예측값이 실제값에 가깝다고만 해서 좋은 모델이라고 단정할 수 없어요. 어떤 종류의 오차에 더 민감한지, 모델이 데이터를 얼마나 잘 설명하는지 등 다양한 관점에서 평가해야 합니다.
💡 회귀모델의 목표: 예측값(ŷ)과 실제값(y)의 차이(오차)를 최소화하여 최적의 모델을 찾는 것입니다. 평가지표는 이 목표 달성 여부를 측정하는 기준이 되죠.
📚 대표적인 회귀모델 평가지표 종류
지금부터 가장 흔히 사용되는 회귀모델 평가지표들을 하나씩 자세히 살펴보겠습니다.
1. MSE (Mean Squared Error, 평균 제곱 오차)
MSE는 가장 기본적인 회귀 평가지표 중 하나입니다. 실제값과 예측값의 차이를 제곱한 후, 이들을 모두 더해 평균을 낸 값이에요. 수식은 다음과 같습니다

- 장점:
– 미분 가능하기 때문에 경사 하강법과 같은 최적화 알고리즘에 널리 사용됩니다.
– 오차가 클수록 제곱으로 인해 더욱 큰 페널티를 부여합니다. - 단점:
– 오차가 제곱되므로 실제 오차의 단위와 달라 직관적인 해석이 어렵습니다. (예: 주택 가격 예측 시 오차 단위가 ‘원’의 제곱이 됨)
– 아웃라이어(이상치)에 매우 민감합니다. 작은 아웃라이어라도 제곱되면 전체 MSE를 크게 증가시킬 수 있어요.
2. RMSE (Root Mean Squared Error, 평균 제곱근 오차)
RMSE는 MSE의 단점을 보완하기 위해 MSE에 제곱근을 취한 값입니다. 수식은 다음과 같습니다
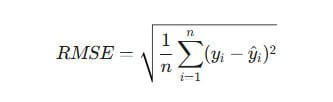
- 장점:
– 오차의 단위가 실제값의 단위와 동일해져 MSE보다 직관적인 해석이 가능합니다. (예: 주택 가격 예측 시 오차 단위가 ‘원’이 됨)
– 큰 오차에 대한 페널티는 유지됩니다.
- 단점:
– MSE와 마찬가지로 아웃라이어에 여전히 민감합니다.

3. MAE (Mean Absolute Error, 평균 절대 오차)
MAE는 실제값과 예측값의 차이에 절대값을 취한 후, 이들을 모두 더해 평균을 낸 값입니다. 수식은 다음과 같습니다

- 장점:
– 오차의 단위가 실제값의 단위와 동일하며, 직관적인 해석이 매우 용이합니다.
– 오차에 절대값을 취하기 때문에 아웃라이어에 덜 민감합니다. 큰 오차도 제곱되지 않고 선형적으로 반영됩니다. - 단점:
– 절대값 함수는 0에서 미분 불가능하기 때문에 MSE나 RMSE처럼 미분을 활용하는 최적화 기법에 바로 적용하기 어렵다는 단점이 있습니다.
⚠️ MSE vs MAE: 아웃라이어가 중요하다면 MSE/RMSE를, 아웃라이어의 영향력을 줄이고 싶다면 MAE를 고려하세요.
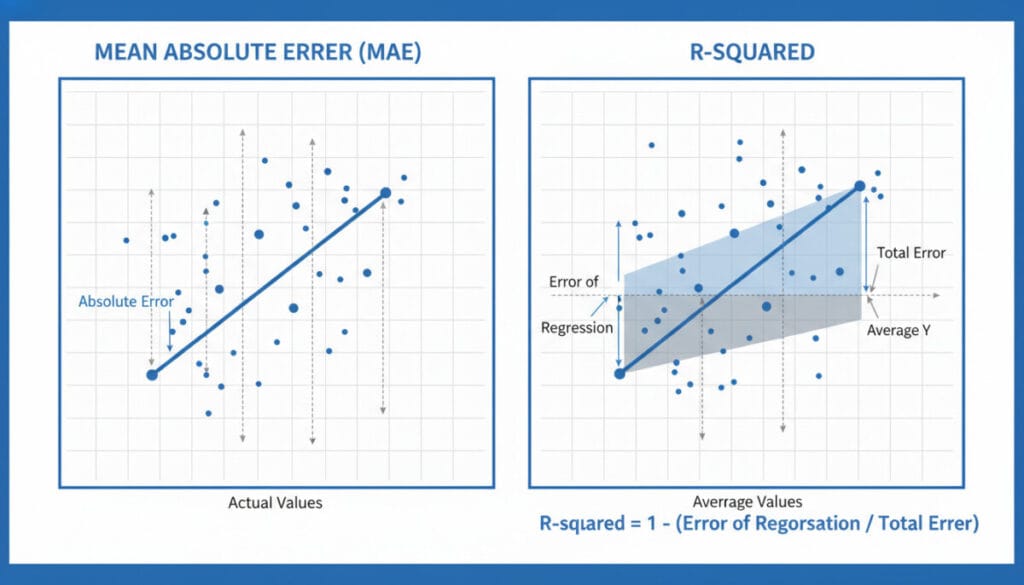
4. R-squared (결정 계수)
R-squared는 모델이 종속 변수(실제값)의 분산을 얼마나 잘 설명하는지를 나타내는 지표입니다. 0부터 1 사이의 값을 가지며, 1에 가까울수록 모델의 설명력이 높다고 판단합니다. 수식은 다음과 같습니다:

- 장점:
– 모델의 설명력을 직관적으로 이해할 수 있습니다. (예: R-squared가 0.8이라면 모델이 종속 변수 분산의 80%를 설명한다고 해석)
– 다양한 모델 간의 상대적인 성능 비교에 유용합니다. - 단점:
– 모델에 독립 변수(특징)가 많아질수록 R-squared 값은 항상 증가하거나 유지됩니다. 이는 모델의 과적합(Overfitting)을 유도할 수 있어 주의해야 합니다.
– 따라서 설명 변수의 수가 다른 모델들을 비교할 때는 R-squared만으로 성능을 판단하기 어렵습니다.
5. Adjusted R-squared (수정 결정 계수)
Adjusted R-squared는 R-squared의 단점, 즉 독립 변수의 개수가 늘어날 때 무조건 값이 증가하는 경향을 보완하기 위해 고안되었습니다. 독립 변수의 개수를 고려하여 R-squared 값을 조정합니다.

- 장점:
– 불필요한 독립 변수가 추가되면 오히려 값이 감소할 수 있어, 과적합을 방지하고 더 정확한 모델 설명력을 평가할 수 있습니다.
– 설명 변수의 수가 다른 모델들을 비교할 때 R-squared보다 더 신뢰할 수 있는 지표입니다. - 단점:
– R-squared와 마찬가지로 통계적인 의미는 있으나, 실제 오차의 크기를 직접적으로 나타내지는 않습니다.
💡 각 평가지표, 언제 어떻게 사용할까요?
다양한 평가지표 중 어떤 것을 선택할지는 모델의 목적과 데이터의 특성에 따라 달라집니다. 다음은 일반적인 가이드라인입니다.
| 상황 | 추천 평가지표 | 설명 |
|---|---|---|
| 아웃라이어가 중요할 때 | MSE, RMSE | 큰 오차에 더 큰 페널티를 부여하므로, 아웃라이어가 모델에 미치는 영향을 중요하게 볼 때 적합합니다. |
| 아웃라이어 영향을 줄이고 싶을 때 | MAE | 절대 오차를 사용해 아웃라이어에 덜 민감하므로, 이상치의 영향 없이 일반적인 오차 수준을 보고 싶을 때 유용합니다. |
| 모델의 설명력을 알고 싶을 때 | R-squared, Adjusted R-squared | 모델이 종속 변수의 변동성을 얼마나 잘 설명하는지 백분율로 나타내어 모델의 전반적인 적합도를 판단할 때 사용합니다. |
| 여러 모델을 비교할 때 | RMSE, Adjusted R-squared | RMSE는 단위가 같아 직관적인 비교가 용이하며, Adjusted R-squared는 변수 개수 변화에 따른 과적합 문제를 보정해 더 공정한 비교를 돕습니다. |
💡 핵심 요약
1. MSE/RMSE는 오차 제곱을 통해 큰 오차(아웃라이어)에 민감하게 반응합니다. RMSE는 단위가 실제값과 같아 직관적입니다.
2. MAE는 오차 절대값을 통해 아웃라이어에 덜 민감하며, 해석이 매우 직관적입니다.
3. R-squared는 모델의 설명력을 0~1 사이 값으로 나타내며, 1에 가까울수록 설명력이 높습니다.
4. Adjusted R-squared는 R-squared의 단점을 보완해 변수 증가에 따른 과적합을 방지하며, 더 정확한 모델 비교를 가능하게 합니다.
이러한 평가지표들을 종합적으로 고려하여 모델의 강점과 약점을 파악하고 최적의 성능을 끌어내는 것이 중요합니다.
❓ 자주 묻는 질문 (FAQ)
Q1: 회귀모델 평가지표는 무조건 낮은 것이 좋은가요?
A1: MSE, RMSE, MAE와 같은 오차 기반 지표는 낮을수록 모델의 예측 오차가 작다는 의미이므로 좋습니다. 하지만 R-squared, Adjusted R-squared와 같은 설명력 기반 지표는 높을수록 모델이 데이터를 잘 설명한다는 의미이므로 좋은 것입니다. 각 지표의 특성을 이해하는 것이 중요해요.
Q2: RMSE와 MAE 중 어떤 것을 더 많이 사용하나요?
A2: 두 지표 모두 널리 사용됩니다. 일반적으로 RMSE는 큰 오차에 더 큰 가중치를 부여하므로, 이상치가 중요한 경우나 예측 오차를 줄이는 것이 최우선 목표일 때 선호됩니다. 반면 MAE는 이상치에 덜 민감하며 오차를 직관적으로 해석하고 싶을 때 유용합니다. 데이터의 특성과 모델의 목적에 따라 선택이 달라져요.
마무리하며…

오늘은 인공지능 회귀모델의 핵심 평가지표인 MSE, RMSE, MAE, R-squared, Adjusted R-squared에 대해 자세히 알아보았습니다.
각 지표가 어떤 의미를 가지며, 어떤 상황에 적합한지 이해하는 것은 단순히 모델을 만드는 것을 넘어, 모델의 성능을 정확히 파악하고 개선하는 데 필수적인 능력입니다.
이 지식들을 바탕으로 여러분의 AI 모델이 더 스마트하고 신뢰성 높게 발전하길 바랍니다. 꾸준히 공부하고 데이터를 탐구하며 인공지능 분야의 진정한 전문가로 성장하시기를 응원합니다!
다음 포스팅에서는 분류 모델의 평가지표에 대해 다뤄볼 예정이니, 많은 기대 부탁드립니다!