
인공지능(AI) 시대의 핵심 기술로 불리는 머신러닝(Machine Learning), 이번 글에서는 본 머신러닝의 기본 개념을 살펴보고, 작동 원리를 이해하며, 우리 실생활에 적용된 사례까지 함께 알아가 보도록 하겠습니다.
1. 머신러닝의 정의: 기계가 데이터를 통해 학습하다
머신러닝은 인공지능의 한 분야로, 컴퓨터가 명시적인 프로그래밍 없이 데이터를 기반으로 스스로 학습하고, 패턴을 발견하며, 이를 통해 미래를 예측하거나 의사결정을 내리는 기술을 의미합니다. 과거에는 개발자가 모든 경우의 수를 고려하여 규칙 기반의 알고리즘을 직접 코딩해야 했습니다. 하지만 머신러닝은 기계가 방대한 양의 데이터로부터 직접 지식이나 규칙을 추출하여 작업을 수행한다는 점에서 패러다임의 전환을 가져왔습니다.
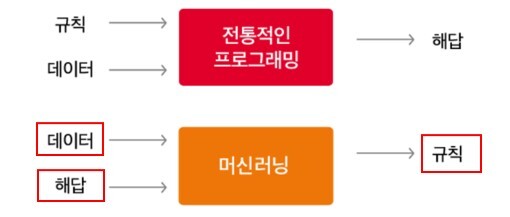
2. 머신러닝의 작동 원리: 학습과 예측의 메커니즘
머신러닝 모델이 지능을 갖추게 되는 과정은 일반적으로 다음과 같은 단계로 이루어집니다.
- 데이터 수집 (Data Collection): 학습의 재료가 되는 데이터를 수집합니다. 데이터의 양과 질이 모델의 성능을 좌우하는 가장 중요한 요소입니다.
- 데이터 전처리 (Data Preprocessing): 수집된 원시 데이터(Raw Data)를 모델이 학습하기 좋은 형태로 정제하고 가공하는 과정입니다. 결측치 처리, 이상치 제거, 데이터 정규화 등의 작업이 포함됩니다.
- 모델 학습 (Model Training): 정제된 데이터를 머신러닝 알고리즘(모델)에 입력하여 패턴, 특성, 규칙 등을 학습시킵니다. 이 단계에서 모델은 데이터의 내재적 구조를 파악하고 최적의 매개변수(Parameter)를 찾아갑니다.
- 모델 평가 (Model Evaluation): 학습된 모델의 성능을 객관적으로 평가하는 단계입니다. 학습에 사용되지 않은 별도의 테스트 데이터를 사용하여 예측의 정확도, 정밀도 등을 측정합니다.
- 예측 및 배포 (Prediction & Deployment): 평가를 통해 검증된 모델을 실제 시스템에 배포하여 새로운 데이터에 대한 예측이나 분류 등의 작업을 수행하게 합니다.
이러한 과정을 통해 머신러닝 모델은 특정 작업에 대한 전문가로 거듭나게 되며, 지속적인 데이터 학습을 통해 성능을 개선해 나갈 수 있습니다.
3. 우리 삶 속에 적용된 머신러닝 활용 사례
머신러닝은 더 이상 연구실에만 머무는 추상적인 개념이 아닙니다. 이미 우리 일상과 산업 전반에 깊숙이 자리 잡고 있으며, 그 영향력은 점차 확대되고 있습니다.
- 추천 시스템 (Recommendation System): 넷플릭스, 유튜브, 아마존 등에서 사용자의 과거 행동 데이터를 분석하여 개인의 취향에 맞는 콘텐츠나 상품을 추천합니다.
- 자연어 처리 (Natural Language Processing, NLP): 스팸 메일 필터링, 챗봇, 번역 서비스, 음성인식 비서(Siri, Google Assistant) 등 인간의 언어를 컴퓨터가 이해하고 처리하는 기술의 근간이 됩니다.
- 이미지 인식 (Image Recognition): 페이스북의 사진 속 인물 자동 태그, 의료 영상(CT, MRI) 분석을 통한 질병 진단, 자율주행 자동차의 객체 탐지 등에 활용됩니다.
- 금융 및 보안: 신용카드 이상 거래 탐지 시스템(FDS), 주가 예측, 대출 심사 평가 등 금융 리스크를 관리하고 보안을 강화하는 데 중요한 역할을 합니다.
결론: AI 시대를 이끄는 핵심 동력

지금까지 머신러닝의 핵심 개념과 작동 원리, 그리고 실제 적용 사례에 대해 알아보았습니다. 머신러닝은 데이터를 가치 있는 정보와 통찰력으로 변환함으로써 비즈니스 효율성을 극대화하고, 과거에는 불가능했던 문제들을 해결하는 핵심 동력으로 작용하고 있습니다.
다음 글에서는 머신러닝의 종류인 지도 학습, 비지도 학습, 강화 학습에 대해서 자세히 알아보도록 하겠습니다~^^





