오늘은 머신러닝의 한 분야이자,
알파고(AlphaGo)를 통해 우리에게 깊은 인상을 남긴 강화학습(Reinforcement Learning)에 대해 완벽하게 정리해 드리려고 합니다.
마치 강아지에게 ‘앉아’를 가르치듯, 보상을 통해 스스로 최적의 행동을 학습하는 강화학습의 세계. 그 기본 개념부터 핵심 알고리즘, 그리고 현실적인 장단점까지, 이 글 하나로 모두 마스터하실 수 있도록 도와드리겠습니다.
1. 강화학습(Reinforcement Learning)이란 무엇일까요?
강화학습은 머신러닝의 세 가지 주요 패러다임(지도학습, 비지도학습, 강화학습) 중 하나입니다. 정답이 적힌 데이터를 보고 학습하는 지도학습이나, 데이터 속의 숨겨진 구조를 찾아내는 비지도학습과는 근본적으로 다릅니다.
강화학습은 에이전트(Agent)가
환경(Environment)과 상호작용하며, ‘어떤 상황에서 어떤 행동을 하는 것이 최적인가?’를 스스로 학습하는 방식입니다.
여기서 핵심은 보상(Reward) 이라는 신호입니다. 에이전트는 더 많은 누적 보상을 얻는 방향으로 자신의 정책(Policy), 즉 행동 전략을 수정해 나갑니다.
간단히 말해, ‘수많은 시행착오를 통해 보상을 최대로 얻는 방법을 터득하는 학습 과정’ 이라고 할 수 있습니다.
2. 강화학습의 핵심 구성 요소
강화학습을 이해하기 위해서는 몇 가지 핵심 용어를 알아야 합니다.
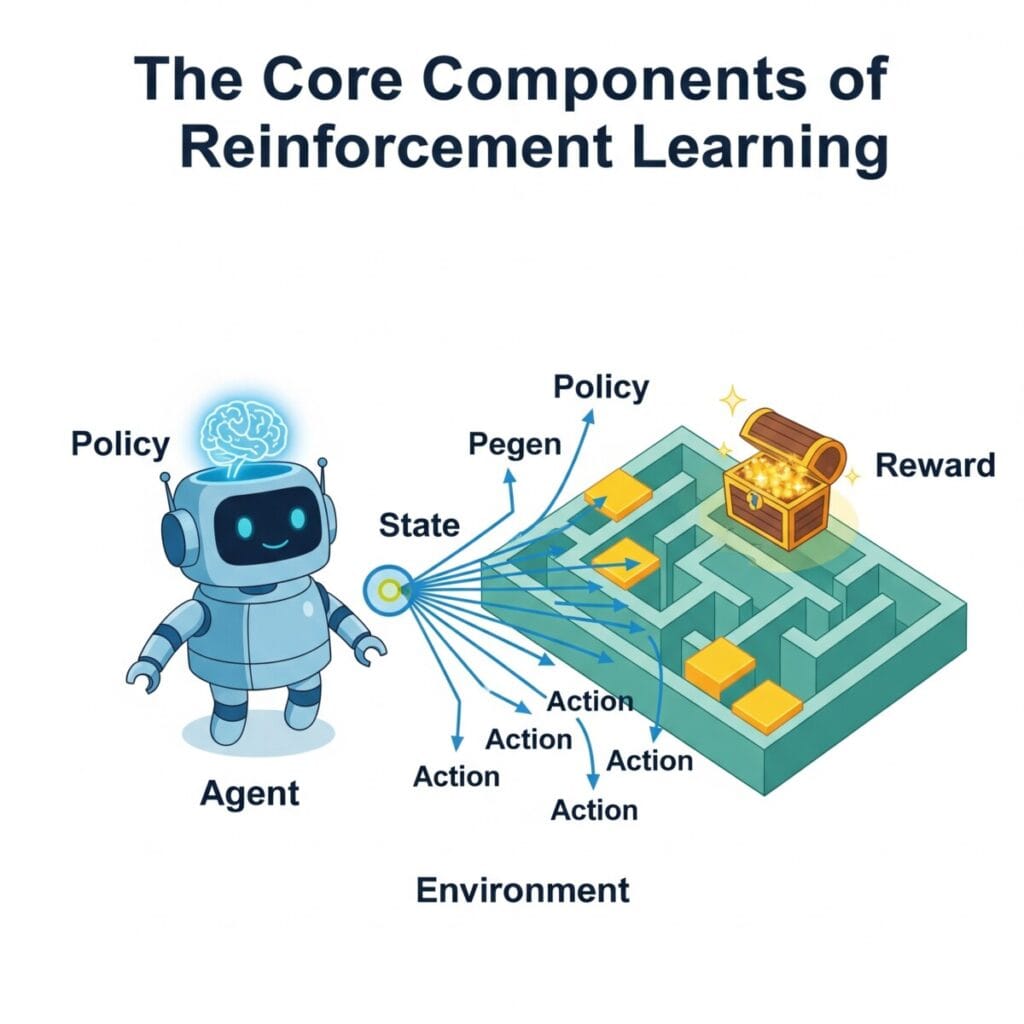
- 에이전트 (Agent): 학습의 주체. 환경 속에서 행동을 결정하고 실행합니다. (예: 게임 플레이어, 로봇)
- 환경 (Environment): 에이전트가 활동하는 무대. 에이전트의 행동에 따라 상태가 변하고 보상을 제공합니다. (예: 게임 맵, 현실 세계)
- 상태 (State, S): 특정 시점의 환경을 나타내는 정보입니다. (예: 체스판의 말 위치, 캐릭터의 현재 위치)
- 행동 (Action, A): 에이전트가 특정 상태에서 취할 수 있는 움직임입니다.
- 보상 (Reward, R): 에이전트가 특정 행동을 취했을 때 환경으로부터 받는 피드백. 긍정적일 수도(플러스 점수), 부정적일 수도(마이너스 점수) 있습니다.
- 정책 (Policy, π): 에이전트의 행동 지침. 특정 상태에서 어떤 행동을 할지 결정하는 전략입니다. 강화학습의 최종 목표는 최적의 정책을 찾는 것입니다.
3. 강화학습의 종류
강화학습은 크게 두 가지 기준으로 분류할 수 있습니다.
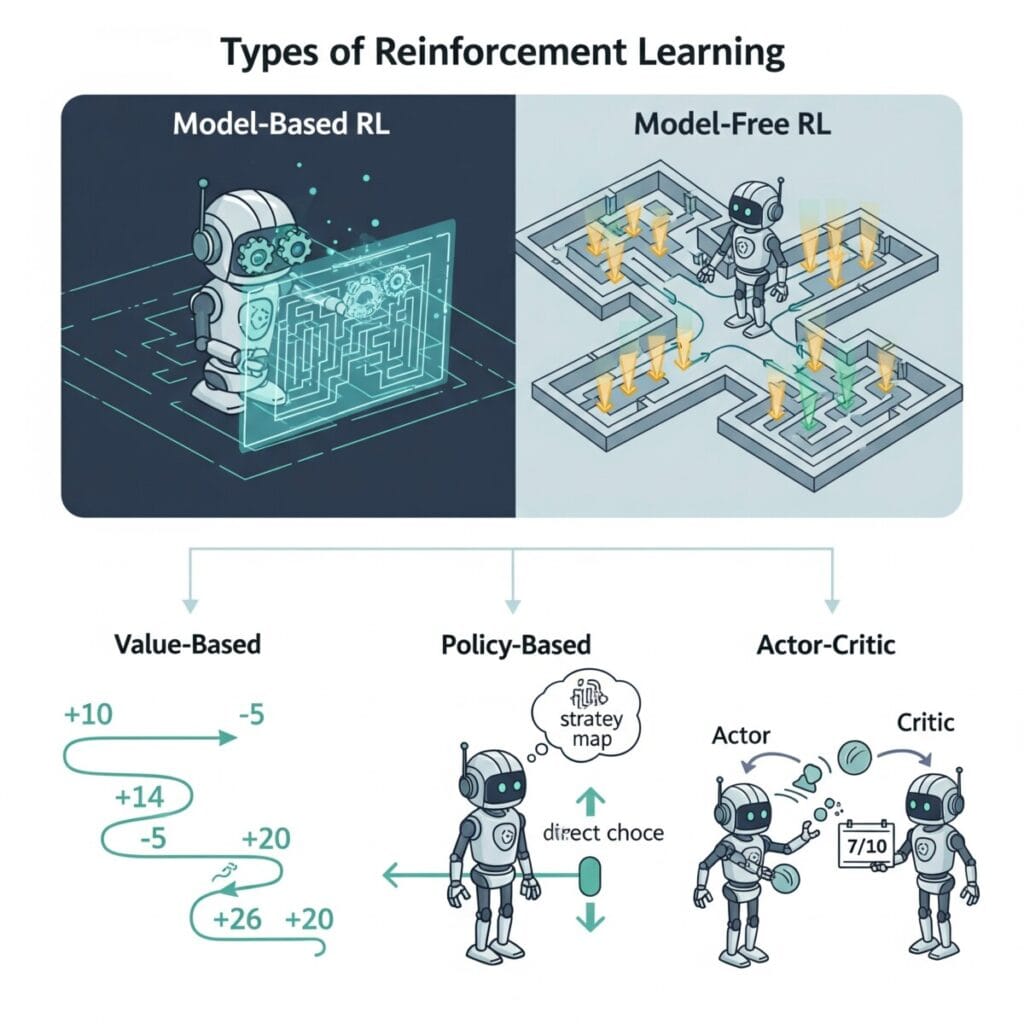
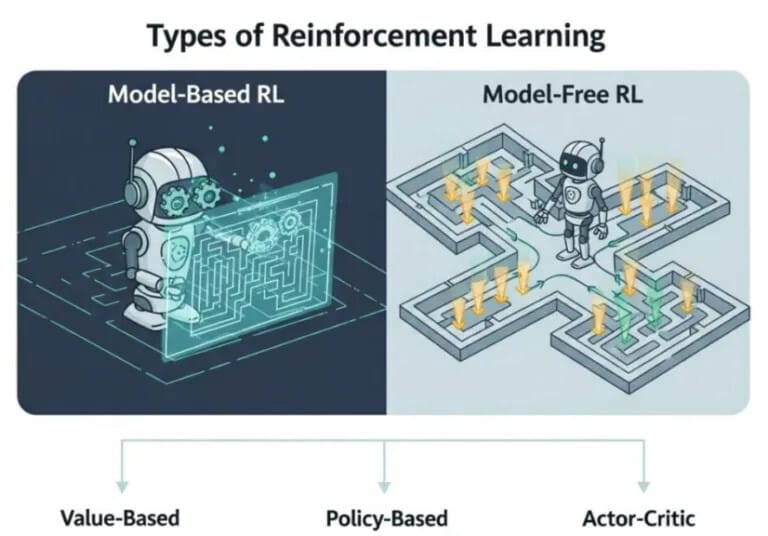
가. 모델의 유무에 따라
- 모델 기반 강화학습 (Model-Based RL): 환경이 어떻게 동작하는지에 대한 ‘모델’을 학습하고, 그 모델을 이용해 최적의 정책을 찾습니다. 즉, 다음 상태와 보상을 예측할 수 있습니다. 데이터 효율성이 좋지만, 모델이 부정확할 경우 성능이 저하될 수 있습니다.
- 모델 프리 강화학습 (Model-Free RL): 환경에 대한 모델 없이, 오직 경험(상태, 행동, 보상)만을 통해 직접 정책을 학습합니다. 대부분의 유명한 알고리즘이 여기에 속하며, 복잡한 환경에 더 잘 적용됩니다.
나. 학습 방식에 따라 (모델 프리 내부)
- 가치 기반 학습 (Value-Based Learning): 각 상태 또는 행동의 가치(미래에 받을 보상의 총합)가 얼마나 되는지를 학습합니다. 그 후, 가장 높은 가치를 가지는 행동을 선택합니다. 대표적으로 Q-러닝이 있습니다.
- 정책 기반 학습 (Policy-Based Learning): 가치를 중간 과정으로 두지 않고, 어떤 상태에서 어떤 행동을 할지에 대한 정책을 직접적으로 학습합니다. 확률적으로 행동을 결정하기 때문에 연속적인 행동 공간에서도 효과적입니다.
- 액터-크리틱 (Actor-Critic): 가치 기반 학습과 정책 기반 학습을 결합한 형태입니다. **액터(Actor)**가 정책을 결정해 행동하고, **크리틱(Critic)**이 그 행동의 가치를 평가하여 액터가 더 나은 결정을 하도록 피드백을 줍니다. 두 방법의 장점을 모두 취해 안정적이고 효율적인 학습이 가능합니다.
4. 대표적인 강화학습 알고리즘
수많은 알고리즘이 있지만, 가장 기본적이고 중요한 몇 가지를 소개합니다.
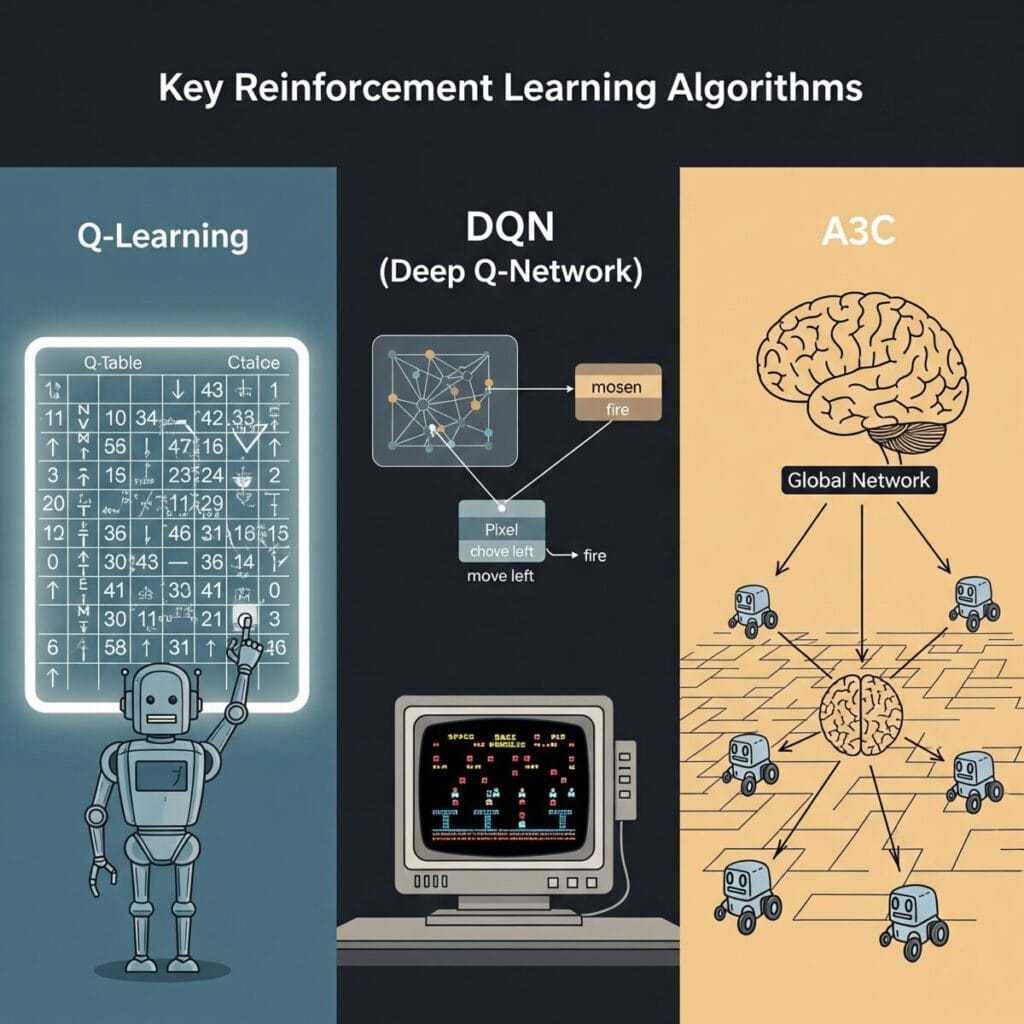
가. Q-러닝 (Q-Learning)
가치 기반, 모델 프리 알고리즘의 대표 주자입니다. 모든 (상태, 행동) 쌍에 대한 가치를 Q-테이블이라는 표에 저장하고, 이 값을 계속해서 업데이트하며 최적의 행동 가치를 찾아갑니다. 간단하고 강력하지만, 상태와 행동의 수가 너무 많아지면(예: 이미지 입력) 테이블을 유지할 수 없다는 한계가 있습니다.
나. DQN (Deep Q-Network)
Q-러닝의 한계를 딥러닝으로 극복한 알고리즘입니다. 구글 딥마인드가 아타리 게임을 정복하며 세상을 놀라게 했죠. Q-테이블 대신 **딥러닝 신경망(Neural Network)**을 사용해 Q-값을 근사(approximate)합니다. 이를 통해 픽셀과 같은 고차원 데이터를 입력으로 받아 바로 행동을 결정할 수 있게 되었습니다.
다. A3C (Asynchronous Advantage Actor-Critic)
액터-크리틱 계열의 대표적인 알고리즘입니다. 여러 명의 에이전트(Worker)가 비동기적으로 동시에 학습을 진행하고, 그 경험을 주기적으로 중앙 관리자(Global Network)에게 공유하여 정책을 업데이트합니다. 이를 통해 학습 속도와 안정성을 크게 향상시켰습니다.
5. 강화학습의 장점과 단점
장점 (Pros)
- 최적의 전략 발견: 사람이 생각하지 못한 창의적이고 최적화된 문제 해결 방법을 찾을 수 있습니다.
- 동적 환경 적응: 정해진 규칙 없이, 변화하는 환경에 스스로 적응하며 학습할 수 있습니다.
- 장기적인 보상 고려: 단기적인 이익이 아닌, 최종 목표 달성을 위한 장기적인 보상을 극대화하는 의사결정이 가능합니다.
- 명시적인 데이터 불필요: 지도학습처럼 ‘정답’ 데이터가 필요 없어 데이터 수집의 부담이 적습니다.
단점 (Cons)
- 학습의 어려움: 학습 과정이 불안정하고, 최적의 해를 찾는 데 매우 오랜 시간이 걸릴 수 있습니다. (Sample Inefficiency)
- 보상 설계의 중요성: 에이전트의 행동을 유도할 보상 함수를 설계하는 것이 매우 어렵고, 잘못된 보상은 의도치 않은 결과를 낳을 수 있습니다.
- 탐험과 활용의 딜레마 (Exploration vs. Exploitation): 현재까지의 최선책을 계속 활용할 것인가, 아니면 더 좋은 방법을 찾기 위해 새로운 시도(탐험)를 할 것인가의 균형을 맞추기 어렵습니다.
6. 마무리하며: 강화학습의 미래

강화학습은 게임(알파고), 로보틱스 제어, 자율주행차의 주행 전략, 자원 관리 최적화 등 복잡한 의사결정이 필요한 수많은 분야에서 놀라운 잠재력을 보여주고 있습니다.
물론, 아직 해결해야 할 과제도 많지만, 시행착오를 통해 스스로 학습하고 성장하는 강화학습의 패러다임은 인공지능이 나아갈 중요한 방향 중 하나임이 틀림없습니다.
오늘 이 글을 통해 강화학습의 큰 그림을 이해하시는 데 도움이 되었기를 바랍니다.